¶主要内容:
- 使用SBT(Simple Build Tool)工具构建项目。
- Scalaz HTTP 模块。
- 创建一个WEB应用程序weKanban。
本书的第二部分开始,将关注于Scala函数式编程的实际应用。现在早已有Web应用框架 Lift 和 Playframework 开构建web应用程序。但是本章介绍的是一个有趣的Scala http库——Scalaz。这个简单的库让你更加专注于函数式web应用的构建,而不用担心全栈的Web框架带来的复杂性问题。
HTTP 请求并产生一个HTTP响应。每个URL端点被映射到一个函数中,这个函数则用来处理request。因为你创建的是一个函数式风格,web应用程序的状态被显式地被指定在每个请求中。这样想的好处是,你可以将web应用程序进行组合或者使用高阶的组合。web框架的对应策略是无状态的和可变的。在本章内容中,你将学习到使用函数式编程来构建一个web应用框架。
要到达终点,首先要知道如何创建一个应用程序,如何使用。或许我们使用过了比较多的构建工具,但是比较标准的构建工具是SBT。这里将介绍如何配置和使用SBT来构建Scala Web项目。
¶6~1〖Building weKanban: a simple web-based kanban board〗P170
你准备构建一个web应用程序——看板娘1 2。主要业务流程有:
- 作为客户,你想要创建一个新的用户故事,这样我可以将故事添加到准备状态。
- 作为开发者,我想要将cards(stories)从一个状态移到另外一个状态,这样我可以对操作进行标记。
在此之前,首先让我们学会使用SBT构建我们的应用程序。
¶6~2〖building Scala applications using Simple Build Tool〗P171
SBT3 是一个Java和Scala的构建工具,完全用Scala编写,你可以用Scala代码或者SBT内建的DSL语言来构建项目和依赖。之所以使用SBT构建的好处定义是来自于强大的功能和类型安全的语言。他和Maven和Ant有所不同,Maven和Ant构建配置写在XML中。
SBT提供了持续的编译和测试,这意味着,SBT会在你的代码发生改变时自动编译和测试。所以你应该使用这些特性在Web服务自动部署上。
下面的一小部分内容将向你介绍SBT,从安装到环境变量,以及SBT的目录结构。我将从构建webKanban项目开始全面介绍。
¶621〖Setting up SBT〗P172
最简单的方式是直接下载4 SBT的相应jar文件,并直接使用脚本运行,依赖于不同的操作系统。
UNIX
创建一个SBT文件,
1 | java -Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled |
把SBT文件放在~/bin文件夹中,并和下载的jar放在一起,配置好环境变量。当然,你需要设置文件的执行权限。
1 | Chmod u+x ~/bin/sbt |
CMSClassUnloadingEnabled表示可以允许垃圾回收机制。
WINDOWS
使用下面命令来创建批文件sbt.bat,
1 | Set SCRIPT_DIR=%~dp0 |
再把下载的jar放置在相同的目录中,并使改目录可以被访问。
MAC
对于MAC的用户则比较简单,使用Homebrew 或者 MacPorts来直接安装:
1 | brew install sbt |
你不用下载jar文件,如果你设置了HTTP代理,你需要传递相应的属性:
1 | java -Dhttp.proxyUser=username -Dhttp.proxyPassword=mypassword -Xmx512M |
¶622〖Understanding the basics of SBT〗P173
对于理解SBT的基础内容比较重要。SBT是一个富特性(feature-rich)的构建工具,本小节的主要目标是理解SBT的基础内容。更多详细内容,请参考 http://scala.sbt.org。
有三种方式通过SBT来构建项目:
- 使用 .sbt 文件来配置项目的构建定义。
- 使用 .scala 文件来构建定义。它允许你可以在配置中编写Scala 代码。
- 使用 .sbt 和 .scala 文件同时构建。
第一种方式是最简单的方式。它是一种DSL定义。但在更加复杂的构建中,你需要用到 .scala 构建文件。这就是为什么通常会看到有 .sbt 和 .scala 两个构建文件在Scala的典型项目中。之后,我将解析什么时候需要用到 .scala文件,现在让我们开始SBT的文件构建路程。
BUILDING THE FIRST SBT BUILD FILE
SBT按照习惯约定工作。你可以在基础目录中看到Scala的源文件,它位于 src/main/scala 和 src/main/java 文件夹中。一个有效的SBT项目的最低要求是在基础目录中要有一个源文件。让我们从创建Hello world!开始。下面代码片段创建了一个空的文件夹test,并创建一个hello world应用:
1 | mkdir test |
趁热打铁,开始对其进行编译和运行。在SBT的命令提示符环境中,你可以调用编译任务来对源文件进行编译。编译好了之后,调用run 命令来运行这个示例。你应该得到如下输出:
1 | run |
SBT智能地选择项目中基础目录中的源文件,运行run任务时,会查找classpath中的所有类中定义了main方法的类。所有编译了的生成的class文件会放置在target目录下。要查看所有SBT的可用任务命令,可以在SBT提示符中输入tasks查看到。
默认地,SBT会使用SBT自带的Scala版本对项目的源文件进行编译。这里使用的是2.10.6。
1 | scala-version |
你可以容易地更改SBT的默认Scala版本,即通过set命令进行。如下命令可以不用SBT命令提示符的情况下改变项目的名称和版本:
1 | set name := "Testing SBT" |
每次你调用set,它会更改项目的设置。简言之,在SBT中,scalaVersion、name 和 version 是预定义的 keys,它们的 values 是String类型。每个keys都是 SettingKey[T] 类型,T就是 值 的运行类型。
¶Settings in SBT
SBT的Settings 就是存储构建定义。它定义了一系列的
Setting[T]的键值对。有三种类型的keys:
SettingKey[T]是value只计算一次的类型。如name 、 scalaVersion。TaskKey[T]不需要每次重新计算的key-value类型,TaskKey用于创建任务,例如编译和打包。InputTask[T]是一个task key,用于接收命令行输入的参数。所有这些预设keys被定义在sbt.Keys对象中。
为了持久化这些设置,可以在SBT命令提示符中调用session save任务。它会将这些设置保存到基础目录下的build.sbt文件中。
1 | cat build.sbt |
现在,你已经创建了你的第一个SBT构建文件。在构建文件中,每一行都是一个表达式,并且每行的表达式都要用空白行隔开,否则,SBT不能对这些表达式进行区分。这些表达式在构建文件中为SBT创建了一些列的设置。SBT的构建定义不是别的,就是表示Setting[T]的一个列表。当所有这些设置被执行,SBT会创建一个不可变的Map键值对。这就是你的构建定义。例如下面的会创建一个Setting[String]设置:
1 | name := "Testing SBT" |
这里的 := 是一个key为name的方法调用,上面的表达式你也可以这样写:
1 | name .:=("Test SBT") |
所有可用的keys被定义在sbt.Keys对象中,在build.sbt文件中会自动为你导入。你也可以在build.sbt内指定要导入的语句,但要放在文件的开头。build.sbt是配置构建设置的重要地方。例如,你可以添加-unchecked和-deprecation值到键scalacOptions里面,使unchecked和deprecation生效:
1 | scalacOptions ++= Seq("-unchecked", "-deprecation") |
方法 ++= 可以让你添加多个值到scalacOptions。这里有一点需要重要说明的是,SBT 构建文件都是类型安全的。key的类型确定了value的类型。例如,organizationHomePage可以设置一个组织的home page,它是一个Option[URL]:
1 | set organizationHomepage := "22" |
目前对于类型安全的构建工具有不少争议,但我认为对于你的代码、构建文件,类型安全是个好东西。对于一些中大型项目,你会为你的系统编写非常大量的代码,而SBT提供的类型安全机制则可以有更快的信息反馈。下一小节你将学习使用SBT来构建一个更加正式的项目。
BUILDING A PROJECT STRUCTURE FOR SBT
如果你此前使用过SBT 0.7+,你会惊讶于SBT并没有创建一个Maven-style风格的的项目结构。但是不用担心,现在你可以有更多的方式来创建你的项目了。你可以使用下面的代码片段来创建所有典型的文件目录:
1 | mkdir -p src/{main,test}/{scala,java,resources} lib project |
它会为一个典型的Scala应用创建所有的目录文件。另外一个选项是,你可以使用SBT插件来创建一个新的项目。一个SBT插件通过添加新的任务和设置来扩展构建定义。因为插件可以用来构建SBT项目,因此它可以作为一个全局插件添加。全局的插件被添加自动添加到所有SBT项目中;添加一个插件到一个项目中,则只限于当前的项目。若要添加为全局的插件,可以创建一下文件:
1 | touch <home-directory>/.sbt/plugins.sbt |
你现在要使用np插件np plug-in来生成一个新的项目。要使用它,你需要将下面的行添加到plugins.sbt:
1 | addSbtPlugin("me.lessis" % "np" % "0.2.0") |
键resolvers告诉SBT到哪里去找这个依赖项,+=表示把一个新的resolvers添加到已有的,函数addSbtPlugin表示添加一个新的插件到SBT构建系统中。现在把下面的行添加的build.sbt文件:
1 | seq(npSettings: _*) |
把它添加到build.sbt表示这个设置将会对所有的SBT项目生效。我们将在不久更详细地介绍SBT的设置。现在我们通过一下命令来创建一个新的项目:
1 | mkdir <your project name> |
插件np也会创建一个默认的build.sbt文件,你可以修改并添加你的设置。
还有另外一个方式是,使用giter8。它是一个命令行工具,通过在Github上发布的模版,用它来生成文件和目录。这慢慢地变成了创建Scala项目的一个标准方式。一旦giter8被安装了,你可以选择一个模版来生成项目的结构。
提示 你不需要在SBT提示符里面执行SBT任务——你可以在命令行里面执行。例如,sbt compile run命令将同时执行compile和run。
不管你如何创建项目结构;它的目录结构看起来和Maven是相似的,因为SBT使用了Maven的目录结构。实际上,如果你在Maven里使用了Scala plug-in来创建一个项目,最终你会得到近似相同的目录结构。如果你的项目包含了Java源文件有包含了Scala源文件,你需要同时有一个java目录位于src/main 和 src/test。
图6.2为一个完整的SBT项目,并展示了所有可能的构建配置。就像你看到的build.sbt一样,它是一个简单构建工具,它允许你设置各种与构建相关的settings和dependencies。dependencies的配置之后将学习到。
提示 有一个争论是如何命名build,如build.sbt 或 build.scala,但实际上你可以使用任何名字。这也意味着,你可以在一个项目中拥有多个.sbt 和 .scala构建文件。
构建文件build.scala带给你SBT的全部能力。你可以在build.scala中编写Scala代码来配置你的构建,而不是使用DSL(Domain Specific Language,领域专用语言)。在旧版本的SBT,配置构建文件仅仅只能使用SBT DSL来编写。但在 “新” SBT中,这个方式被推荐用于简单的构建定义(build.sbt 文件),只有当被需要时,则再创建 build.scala。对于你现在的项目weKanban,你将会两个都用到。
另外一个文件 build.properties 允许你设置SBT的版本,并用于该项目中。例如,我的build.properties配置如下:
1 | sbt.version=0.12.0 |
设置的版本会被用于项目中。project/plugins.sbt 文件,典型地用于配置SBT插件的。另外请注意,项目中用build.scala 和 plugin.sbt来构建项目是可选的,只有真正被用到时才需要添加。target文件夹则是用于存储生成的classes、.jar文件;其它的artifacts (如project、java、resources、scala等文件夹)则由配置生成。

注意 总是从.sbt文件开始构建项目,.scala文件仅仅只有在被需要时添加。经验法则是,.sbt文件定义所有的设置,.scala文件则是当你需要引入一个变量、对象、方法定义时使用。在多项目的工程中,build.scala文件被用于定义功能的设置和任务。
SBT项目结构是递归的。也就是说,一个项目如果在另外一个项目内,它将遵循父级项目的构建。并且project/project知道如何构建父级项目。.scala构建配置是一个SBT项目。
ADDING DEPENDENCIES AND CUSTOM TASKS
使用SBT,你有两种方式来管理依赖关系(dependencies): 手动 和 自动。对于手动的方式,则是 拷贝.jar文件到 lib 文件夹,SBT会在编译、运行、测试时,将这些 .jar添加到 classpath环境变量。缺点就是,你需要负责管理这些 .jar、更新和添加.jar。在SBT项目中,最常见和被推荐的方式是让SBT来为你管理这些依赖关系。对于自动的方式,你需要在构建文件中指定依赖,然后SBT处理这些结果。例如,下面在build.sbt添加一个jetty依赖关系:
1 | libraryDependencies += "org.eclipse.jetty" % "jetty-server" % "9.3.7.v20160115" |
其中,libraryDependencies 是 settings 的 key,用于添加依赖项,并让SBT自动处理。该 key 将存储所以依赖关系的序列对。下面为build.sbt依赖关系构建 value 的格式:
1 | groupID % artifactID % version |
这种依赖引用的方式,实际上就是Maven POM文件的处理方式。任何依赖由上面的三个属性唯一标识。
注意 如果你在groupID 后面使用 %% ,SBT会自动为artifactID添加上版本号,如 "org.scalatest" %% "scalatest" % "3.0.0-M7",它实际上等价于 "org.scalatest" % "scalatest_2.10" % "3.0.0-M7"。每个scala库都有不同的SBT版本。
SBT使用了一系列的resolvers来链接项目依赖并下载。在SBT中,一个resolver是依赖host的一个URL(和Maven repository类似)。默认地,SBT使用Maven2 和 Typesafe ivy releases5 来处理这些依赖。你可以使用resolvers 来添加一个存在的依赖链接。
¶Using SBT on existing Maven Scala projects
以为SBT沿用了Maven项目结构并使用了Maven依赖,为Maven项目创建SBT则显得容易。你如果在构建文件中使用了
externalPom()方法,SBT可以读取定义在POM文件的依赖定义。注意,你仍然需要自定repository:
可选地,你可以创建一个项目定义文件,配置其使用本地的Maven仓库:
SBT自动地拾取构建文件的改变,你也可以显式地运行 reload 和 update 任务来重新编译并处理依赖。
注意 SBT使用了Apache的Ivy实现和管理依赖关系。Apache Ivy是一个灵活的、可配置的依赖管理器。
你也可以声明依赖的作用范围scope,即在依赖声明的版本号后面额外添加一个配置。如下面为specs库添加一个依赖声明,但仅仅作用于test配置:
1 | libraryDependencies += "org.scala-tools.testing" % "specs" % "1.6.2" % "test" |
现在,该依赖项仅会作用于src/main/test,下面是build.sbt改变后的代码:
1 | scalaVersion := "2.10.0" |
另外一个最常的SBT操作就是为项目创建自定义任务。对于自定义任务,.scala构建定义文件被用到,因为.sbt构建文件不支持。创建自定义任务遵循以下几个步骤:
- 创建一个TaskKey。
- 为TaskKey提供一个 value。
- 把任务放置在项目下的.scala构建文件。
TaskKey 和 SettingKey相似,但它是用来定义任务的。主要不同是,SettingKey 的 value 只被执行一次,但 TaskKey 的 value在该key每次被访问时执行。这就使得tasks可以一次又一次地被执行。但两者都会产生settings(key-value 对)。下面展示了一个简单的build.scala文件,该文件仅定义了一个hello world任务:
1 | import sbt._ |
项目的名称只是一个例子,文件 Build.scala应该在example/project目录下。首先创建一个新的TaskKey,包含name和description,这里的name参数为hello,并被用于命令提示符调用。声明一个闭包来定义一个任务helloTask,并被用于所在的项目。
项目的构建定义应该继承sbt.Build,继承以访问默认的构建设置。每个构建定义应该定义一个或多个项目。这里只有一个项目,对于多项目工程,你应该在这里声明所有的子项目。多项目的构建定义超出了本书的范围,你可以在 这里 获取到更多详细内容。因为要将hello任务添加到项目,你需要在该项目的SBT环境下执行如下操作:

¶Debugging project definition in interactive mode
取决于你所工作的scala项目的大小,构建定义会变得非常大。为了在定义中对任何问题进行故障排除,SBT提供了一个task叫做
console-project。如果你在SBT控制台内执行该构建命令,SBT会构建定义中载入Scala解析器。如果你运行 console-project 命令,它会加载所有你的构建和插件定义,并使得它们可以访问。在example例子中运行console-project ,你可以访问它的 settings 和 tasks:
2
3
4
5
6
7
res2: String = Testing SBT
scala> get(scalaVersion)
res3: String = 2.10.0
scala> runTask(hello, currentState)
Hello World
res11: (sbt.State, Unit) = (sbt.State@4fae46d5,())runTask 用于运行构建中的任务。在这里的task是 hello task。currentState 跟踪SBT的命令。
相似地,你可以运行 console 构建命令的 Scala 解析器。
截至目前,你已经有了所有有关SBT的基础知识内容,以及用它来构建一个web应用。下一小节开始构建webKanban项目结构,以及如何使用SBT来构建web应用。
¶Setting up the weKanban project with SBT
为了建立weKanban项目,首先创建如下项目结构。

除了添加了一个webapp之外,项目结构和 Figure 6.2相同。
首先是设置SBT的版本,在 weKanban 项目 project/build.properties 中:
1 | sbt.version = 0.12.0 |
文件build.properties的唯一目的就是设置 sbt.version 版本号。这里设置为 0.12.0。如果本地SBT版本不可用,则会自动下载该文件定义的相应的版本。下一步,添加与项目相关的构建信息到build.sbt文件:
1 | name := "weKanban" |
记住每个settings表达式要空一行,SBT才能解释.sbt文件的每个表达式。当SBT加载一个 .sbt 文件,便为每个定义在 .sbt 文件中的所有表达式创建了一个Seq[Setting[T]]。
为了让项目支持web,你需要使用 SBT web插件 ,该插件使用的是jetty服务器,并添加tasks到SBT,以启动、结束jetty服务器。下面是添加该插件的表达式:
1 | libraryDependencies <+= sbtVersion { v => "com.github.siasia" %% "xsbt-web-plugin" % (v+"-0.2.11.1") |
这个web插件作为一个依赖添加到项目中,添加一个插件,实际上就是在构建定义中添加一个库依赖。其中方法 <+= 表示从其他keys计算一个新的list集合。这里的 sbtVersion,用于决定确切的插件版本。实际上,它的apply语法糖就是用来统计插件的版本的。
1 | libraryDependencies <+= sbtVersion.apply { v => "com.github.siasia" %% "xsbt-web-plugin" % (v+"-0.2.11.1") |
在使用插件启动、结束web服务之前,你还要添加相应的jetty依赖项到build.sbt中:
1 | libraryDependencies ++= Seq( |
注意,jetty依赖项被添加到container scope,另外,jetty-web被添加到test scope。这里的scope 指的是sbt 键-值的上下文范围。你可以把scope认为是一个命名空间机制(name-spacing mechanism),表示一个key,在不同的范围(scopes)有不同的值。例如,在一个多项目构建中,你可以在不同的项目中,设置不同sbtVersion版本。这点对于插件来说非常有用,因为不同插件创建的任务不会和其他任务发生冲突。要将插件的所有任务引入到你的项目中,你必须将插件项目的settings,导入到你的build.sbt文件:
1 | seq(com.github.siasia.WebPlugin.webSettings :_*) |
在SBT命令提示符中,如果没有出错,将看到下面的附加任务(你可能需要执行reload):
1 | container: |
注意 该插件的新版本已经迁移,请以新版本为准。
为了运行该web服务,请在控制台中运行container:start任务,它将开启jetty端口为8080服务。因为sbt开启的jetty server的一个分支,你可以在控制台上执行其它构建动作。在浏览器http://localhost:8080/,你可以看到一个webapp的文件夹。至此,你已经完成了你的构建设置。你可能需要添加更多的依赖项。现在,让我们转换话题,谈论一下Scalaz,一个用于构建Scala web应用的框架。
¶6~3〖Introducing the Scalaz HTTP module〗P183
Scalaz(读作:“Scala-zed”)是一个用Scala编写的库。Scalaz背后的思想是提供一个标准Scala API所没有提供的通用函数。本小节介绍的HTTP模块就是来源于Scalaz核心部分。当你使用HTTP模块功能时,我们将接触到Scalaz的核心APIs。下面首先讲解下Scalaz中会被用于webKanban项目的模块内容。
¶631〖How the Scalaz HTTP library works〗P183
简单来说,Scalaz HTTP 库就是Java Servlet APIs的一个转换。Scalaz HTTP的主要目的就是实现一个转换一个HTTP请求为一个响应的方式。实际上就是我们第6.1所讲的,将HTTP URLs映射为functions,该function以request作为参数,response作为返回值。下面是一个Scalaz中的web Application 特质:
1 | trait Application[IN[_], OUT[_]] { |
特质Application定义了一个单一的apply方法,该方法接收一个request实例,并返回一个response实例。实现该方法,创建一个工厂方法,接收一个用于转换request为response的function参数。如下:
1 | object Application { |
方法application通过传递函数,接收一个请求,并返回一个响应实例,最终创建一个Application实例。特质Application里面的参数看起来和以往的有点不一样,在Scala中,称之为 高级类类型(higher-kinded types) 。你可以认为是它是参数类型的指定类型(类型的类型)。这里很难理解,下面分解讲述下:
¶Another example of higher-kinded types
在Scalaz库中,我们已经看过了 高级类类型,现在通过学历一个例子,来理解为什么高级类类型如此强大。现在知道,高级类类型就是一个 类型组,以及我们可以编写一个函数来操作该 类型组,高级类类型是该函数的常见实现形式。例如,我们要实现一个函数sum,该函数可以操作Scala集合里面的所有类型。如何实现?通常的实现方式是:
2
def sumArray(xs: Array[Int]): Int = xs.foldLeft(0)(_ + _)但是这种实现方式并不高效,但如果我们为所有集合类型创建一个抽象,并编写一个通用的sum函数作用于这个抽象。也就是说,让sum函数接收一个包含所有类型的实现+function。为了实现这个功能,创建一个特质Summable,参数化类型为A:
2
3
4
def plus(a1: A, a2: A): A
def init: A
}现在,所有类型都支持+function,并实现这个特质。下面是Int和String类型的实现:
2
3
4
5
6
7
8
def plus(a1: Int, a2: Int): Int = a1 + a2
def init: Int = 0
}
object StringSummable extends Summable[String] {
def plus(a1: String, a2: String): String = a1 + a2
def init: String = ""
}类似地,你可以实现其它类型。现在,要实现所有集合类型的sum逻辑,使用foldLeft函数,但是这时应该首先创建高级类类型foldLeft函数的抽象:
2
3
def foldLeft[A](xs: F[A], m: Summable[A]) : A
}现在为每个集合类型实现该特质:
2
3
4
5
6
7
8
def foldLeft[A](xs:List[A],m:Summable[A]) =
xs.foldLeft(m.init)(m.plus)
}
object ArrayFoldLeft extends Foldable[Array] {
def foldLeft[A](xs:Array[A],m:Summable[A]) =
xs.foldLeft(m.init)(m.plus)
}然后使用该特质,实现你的sum函数,你的通用sum函数接收三个参数:集合、foldable特质的实例、给定的Summable特质类型:
这里你为集合类型和集合接收类型,类型参数化sum函数。现在处理string数组和整形列表,你可以使用下面的操作:
2
sum(Array("one", "two", "three"), ArrayFoldLeft, StringSummable)不可否认,这个sum函数看起来有点冗余,还不如
sum(List(1,2,3))和sum(Array("one","two","three"))来得清楚,不过我们会在下个章节进行定义实现。在小规模上下文中,这种方式看起来做了大量的工作,但在大规模的上下文,这是创建抽象的强大方式,你会在下个章节看到一些真是案例。
不管是request或者response,都要从输入流和输出流进行HTTP参数的读写。但是如果我们能够把输入、输出流看作一个集合,岂不妙哉?request和response都包含集合类型byte,这样我们可以对此使用所有的集合API方法。Scalaz特别允许使用类型参数。开箱即用,你可以使用scala.collection.Stream 或 scala.collection.Iterator 参数化Request 或 Response。下面是调用application方法的一种方式:
1 | Application.application { req: Request[Stream] => |
这样做的好处是,你可以使用所有集合API方法处理读、写,而不用太关心输入、输出流。又因为Scala的Stream是一个 nonstrict collection(也称为lazy collection,表示集合不会马上执行,仅在被真正调用时执行),你可以在你需要它的时候进行读取。既然这样,为什么还需要一个高级类类型(higher-kinded type)?因为Stream是一个集合,拥有自己的参数类型,你需要指明Stream是那个参数的。这里,Stream是byte的,因此,参数IN[_] 和 OUT[_] 在运行时会被调用为Stream[Byte]。
注意 从inputStream 到 Request[Stream] 的转换,Scalaz HTTP模块中,通过调用scalaz.http.InputStream实现。该类使用Scalaz核心库将inputStream 转换为Scala Stream。
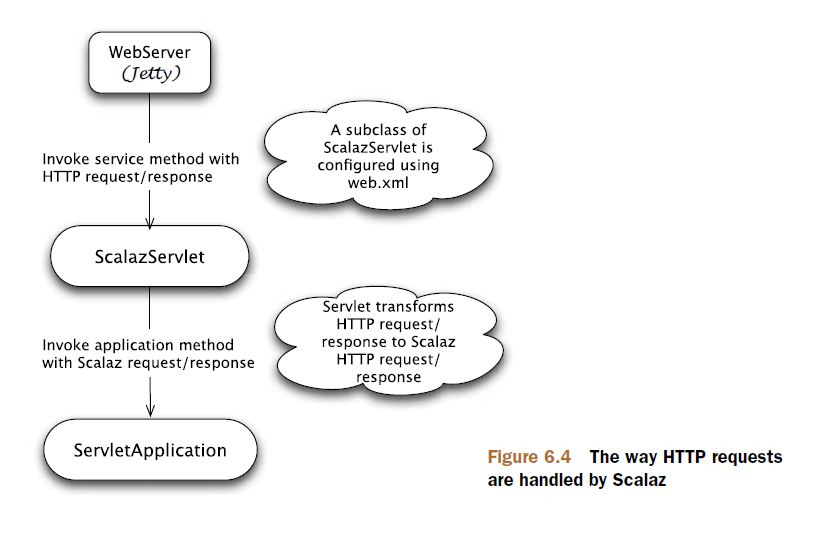
要在Jetty或其它容器中部署你的web应用,你必须熟悉Java Servlet API。前面提及到,Scalaz提供了对Java Servlets的一个封装,因此使用时,不需要过多关心Servlet。图 Figure 6.4 展示了Web容器中,HTTP请求在Scalaz中是如何处理的。
和标准Java web应用一样,Scalaz使用web.xml配置。典型地,所有URLs映射为scalaz.http.servlet.ScalazServlet的子类。在这里,你会使用到scalaz.http.servlet.StreamStreamServlet。通常,Servlet通过application类名配置,并处理所有的request和response。在weKanban应用中,你需要写application。Servlet类的主要职责是,实例化application类,并将HTTP servlet request 和 servlet response 转换为 Scalaz的 scalaz.http.request.Request 和 scalaz.http.response.Response 对象。
当web服务接收一个HTTP请求,它将调用ScalazServlet的service方法。该service方法内实现了从HTTP servlet request到Scalaz Request object的转换,并调用web.xml配置的Application特质里面的application方法。application方法一旦返回Scalaz response,它将该response object 在此转换为HTTP servlet response,并反馈给web 服务器,最终反馈给服务器的调用者。带着这些新只是,让我们在SBT配置Scalaz,之后,你就可以实现你的webKanban应用了。
¶Servlet lifecycle
Servlet的声明周期,由其部署的Web容器所控制。当容器接收一个请求并映射到一个Servlet,容器处理下面几个步骤:
- 如果Servlet实例不存在,创建一个。
- 调用Servlet里面的init方法,初始化该实例。你可以在所处的Servlet接收请求之前,重载该init方法。你也可以将参数传递给init方法。ScalazServlet重载该init方法,并通过该方法参数初始化application类。
- Servlet的service方法,通过传递request 和 response对象进行调用。典型地,一些基于Servlet的框架就是通过重载service方法来调用框架里面的指定的类。例如,ScalazServlet,service方法实现了将HTTP request 、response转换为Scalaz 指定的request、reponse实例,并调用application类处理请求。每个基于Scalaz的web应用都会提供该application的实现。
¶632〖Configuring Scalaz with SBT〗P187
要在SBT中配置Scalaz,Scalaz必须作为一个依赖项添加到你的webKanbanProjectDefinition.scala文件中。下面清单为Scalaz依赖项配置:
1 | name := "weKanban" |
添加完依赖项,当你在scala console 进行reload 或者 update,SBT会从repository下载需要的 Scalaz .jar文件。SBT会自动插件于当前Scala版本兼容的依赖版本。注意,在构建定义中,对于scalaz-core 和 scalaz-http 使用了 %% 而不是 %。这表示SBT会查找与当前Scala版本相匹配的依赖项。如果配置了多个Scala版本,它会为每个版本下载对应的依赖。理想的情况下,你应该使用这种方式来构建项目,但实际上,并不是所有的依赖项都有相对应的Scala兼容。
在前面小节介绍了Scalaz是如何在Java web server环境工作的,现在我们开始进行配置。首先要构建web.xml文件,对于该文件,不会做太多的介绍。在web.xml文件中有两个比较重要的需要配置的是,Scalaz Servlet 和 application类。下面列出该文件的内容:
1 |
|
这里,你可以使用StreamStreamServlet作为你的Servlet类。该Servlet会创建scala.collection.Stream类型的request 和 response。com.kanban.application.WeKanbanApplication为所使用的application。当Scalaz初始化后,application传递init-param里面的参数用于初始化。最后,保存web.xml到src/webapp/WEB-INF中。
开运行该应用之前,你还需要创建WeKanbanApplication。
¶633〖Building your first web page using Scalaz〗P189
你的application类需要继承scalaz.http.servlet.StreamStreamServletApplication特质。该特质声明了scalaz.http.servlet.ServletApplication的抽象,实例化这个特质,就完成了设置。
¶What if I want to roll my own servlet?
通过继承ScalazServlet可以很容易地创建一个servlet。你所要做的事情是,为request和response提供参数类型值,以及提供application的实现类型。例如,下面是你使用的StreamStreamServlet的源代码:
2
ScalazServlet[Stream,Stream,StreamStreamServletApplication](classOf[StreamStreamServletApplication])因为
StreamStreamServletApplication为application类,继承该类作为application。application类唯一要求是提供一个ServletApplication的方法或者值调用application。
特质ServletApplication定义的唯一抽象方法是:
1 | def application(implicit servlet: HttpServlet, |
因为你使用一个Servlet来处理HTTP request 和 response,Scalaz为HttpServlet 和 HttpServletRequest提供了访问。
该方法看起来不同的地方是,在参数前面使用了implicit关键字。声明implicit参数6的优雅之处在于,如果该方法漏掉了隐式参数(implicit parameters),编译器会在闭包环境中,自动查找与之匹配的类型参数,提供给该方法作为此参数。Scala的Implicit是一个强大的概念。第7章将深入了解该内容。我想你早已经实现了Scalaz application类。
1 | final class WeKanbanApplication extends StreamStreamServletApplication { |
继承了StreamStreamServletApplication来创建你的application类,它由Scalaz servlet执行处理所有的HTTP request 和 response。唯一的抽象值是要实现application,这里通过实现application方法处理实现。现在,该方法不作任何事情。
要从web上下文(这里是src/main/webapp)载入静态资源,Scalaz提供了一个很有用的方法resource。通过该方法,你可以载入任何存在的资源请求:
1 | HttpServlet.resource(x => OK << x.toStream, NotFound.xhtml) |
这里resource方法会在关联的上下文环境中加载资源,如果找到,执行第一个参数进行传递。第一个参数是一个函数,该函数接收Iterator[Byte]并返回一个Response[Stream]。因此,上述代码和下面等价:
1 | def found(x: Iterator[Byte]) : Response[Stream] = OK << x.toStream |
OK(scalaz.http.response.OK)是一个HTTP状态code伴生类(case classes),它对应于状态code 200。当你在一个Scalaz状态代码调用<<方法,它会转换为一个空的Scalaz Response对象。一旦转换为Response对象,<<会将stream流追加到response。使用OK << x.toStream,你由请求资源创建了一个Scalaz Response对象。类似地,NotFound也是一个伴生类,表示HTTP状态404;当调用xhtml方法,它隐式地转换为 "application/xhtml+xml"标头的Scalaz Response。这是使用高阶函数和组合函数的一个很好的例子。第四章内容详细地讨论了高阶函数和函数组合。将上述这些代码片段组合在一起后,代码如下:
1 | package com.kanban.application |
WebkankanApplication即为Servlet的 application,它通过继承StreamStreamServletApplication特质实现。
StreamStreamServletApplication特质定义了类型为ServletApplication的一个单一的抽象值application,你需要重载该值实现自己的application。
ServletApplication特质也定义了一个抽象方法,叫做application,该方法接收servlet,HTTP request,以及Scalaz请求作为参数。该方法是所有基于Scalaz web应用程序的核心,它的调用通过映射为ScalazServlet的请求实现。
到目前为止,你的应用仅仅只能处理静态上下文(下一章实现其它内容),已经通过resource方法来接收两个参数。该方法的第一个参数是一个函数,Iterator[Byte] => A(这里指Stream) 会载入上下文静态资源请求,并作为bytes输入。在内嵌函数found中,实现了将该Iterator[Byte]转换为Scalaz Response得到相应内容;第二个参数为另一个函数,该函数用于当static 上下文不存在时被执行。NotFound是一个伴生类,它表示HTTP状态代码404,以及xhtml会创建一个404的Scalaz Response。
下面让我们创建一个index.html文件,该文件位于src/main/webapp,用于web应用的默认界面:
1 | <html> |
现在进入你的SBT控制台,并运行jetty-run构建动作,将开启jetty服务,并将你的web应用部署在服务器上。在浏览器地址栏输入 http://localhost:8080/index.html ,将看到该文件页面内容。
注意 新版的jetty插件已经迁移,更多请查看 https://github.com/earldouglas/xsbt-web-plugin。此处jetty执行命令为jetty:start 以及 jetty:stop命令。
现在,基于SBT和Scalaz web应用已经搭建起来了,我们将继续前进学习更多内容。
¶6~4〖Summary〗P192
本章是你构建中小型Scala应用的第一步。第一次离开RPEL环境来构建一个Scala应用。你使用了SBT。你学习了如何用它工作,如何配置,如何管理依赖来构建大型Scala应用。你还学习了用Scalaz来构建你的Web应用程序。还学习了函数式编程是如何应用于web应用中。以及,Scalaz中使用了Scala的高阶函数和模式匹配暴露优秀的APIs。
本章提供了处理各种Scala工具来构建应用的基础知识。在本章,你花了大部分的时间来学习构建 webKanban应用,但不能存储数据。你需要想出一个存储的idea。下一章将探讨Scala在数据库方面的一些有用的工具,一次完成我们的web应用开发。
- “Kanban”. ↩
- David J. Anderson, Kanban: Successful Evolutionary Change for Your Technology Business, Blue Hole Press, April 7, 2010. ↩
- Install, features, and getting started, SBT 0.12.1, http://scala-sbt.org. ↩
- SBT download, http://mng.bz/1E7x. ↩
- Index of ivy-releases, http://repo.typesafe.com/typesafe/ivy-releases. ↩
- David R. MacIver, “An Introduction to Implicit Arguments,” March 3, 2008, http://mng.bz/TqwD. ↩