现在的AI技术发展真是一日千里,在目前企业庞大的资金博弈的前提下,拼的是谁的能耗成本更低、速度更快、效率更高、迭代更友好,谁率先打破摩尔定律,谁将会成为事实上的标准。作为普通程序员只能被动作为旁观者参与其中。先让子弹飞一会。
¶Ollama 介绍
Ollama是一个专注于大语言模型(LLM, Large Language Models)应用的开源方案,旨在帮助开发者轻松部署和使用私有的大型语言模型,而无需依赖外部的云端服务或外部API,这些模型不仅仅只有包括Meta Llama Model,也提供其他一些Open LLM Model,像是Llama 3.3,Phi 3,Mistral,Gemma 2。该方案的核心目的是提供高效、安全、可控的LLM推论环境建制。大致上有以下特性:
¶采用本地机器运行
Ollama支持在自己的设备上载入模型,无需将数据上传至云端,确保数据隐私与安全。
通过优化模型运行效率,即使在资源有限的设备上也能流畅进行推论。
¶开源与可定制化
Ollama是一个采用MIT License的开源方案,允许开发者根据自己的需求进行修改与扩展。开发者可以将其与其他应用整合,创建自定义的AI解决方案。
¶支持跨平台
提供针对对中操作系统(如Windows、macOS和Linux)的支持,使其能够适应不同的开发环境。
¶提供API开发与整合
提供简单易用的API和工具,帮助开发者快速集成语言模型功能到他们的应用中。
¶隐私与安全性
由于所有运算都在本地完成,无需依赖外部服务器,数据泄露的风险大大降低。
Ollama 的出现满足了对数据敏感性高或对云端依赖性有限的应用需求,如企业内部工具、教育应用或个人隐私保护需求。如果需要更深入的技术细节或具体的使用案例,可以参考该专案的官方文档或Github页面。
¶Ubuntu Linux 安装Ollama
Ubuntu可通过官方标准脚本进行安装,方法如下:
1 | sudo apt-get update -y |
¶启动Ollama服务
脚本执行完成服务已注册入systemd并启动,执行如下命令查看模型列表:
1 | ollama list |
¶Ollama pull 下载 llama 3.2 3b模型
上面的服务不能关掉,然后按照官方的doc介绍,执行ollama pull llama3.2就会下载模型了,需要2GB左右的磁盘空间,不指定版本的话预设是3b的模型,可以单用CPU执行,如果有GPU的话大约需要4GB的VRAM即可,下载完成后的画面如下:
1 | ollama pull llama3.2 |
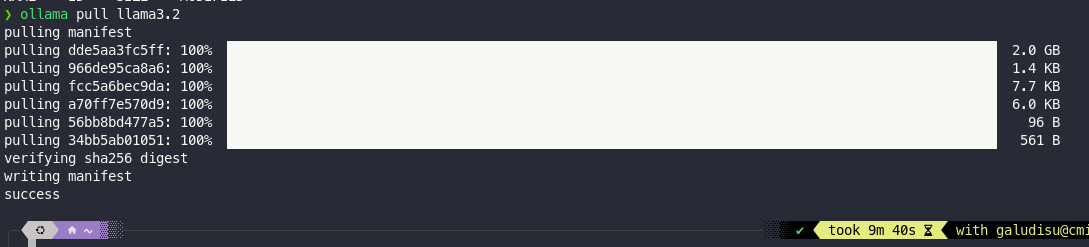
完成以后也可以透过ollama list列出可用的模型,概念与Docker Image一样,
1 | ollama list |

¶通过提示词调用Ollama LL推理
1 | ollama run llama3.2 |
¶通过Rest API呼叫Ollama LLM推理
如果你需要集成到第三方服务中(如alibaba cloud nacos),Ollama可以直接通过Rest API 指定Model进行推论,通过CURL调用:
1 | curl http://127.0.0.1:11434/api/generate -d '{ |
也可以通过对话的方式进行
1 | curl http://127.0.0.1:11434/api/chat -d '{ |

¶Ollama执行llama 3.2 3b在GPU的耗能情况
2024 NVIDIA Compoutex黄仁勋执行长发表了NIM架构,使得使用者可以在云端或自己的服务器建立AI推论微服务,并且可以整合K8S云原生动态扩展机制。
可以由如下命令查看云服务器下GPU的编排资源情况:
1 | docker run --run --runtime=nvidia --gpus all ubuntu nvidia-smi |